While Part 1 “rants” about how function-based machine learning overwhelms data research, this part aims at future opportunities.

Many of my childhood friends and I counted ourselves lucky to own a copy of the A Hundred Thousand Whys (Chinese: 十万个为什么), a children’s science book series. It was the only child-friendly encyclopedia you could find in the 70s/80s in China. The book series originated from a book with the same name authored by a Ukrainian writer Mikhail ll’in (Russian: М. Ильи́н). The fact that our parents invested half a month salary on these books in those difficult years showed how much they struggled to answer our never-ending questions of whys.
Reasoning is a very important part of the learning process. We humans and other animals learn very quickly from direct experiences for survival. At the same time, abstract knowledge is the core of our human intelligence. We discover rules and develop theories from our observations and experiments so to generalise our findings and use them for situations other than our initial observations. It is believed that “the power of generalization is a property that comes with neural networks” and “abstraction is often attributed to humans and the development of the language”. A conventional function-based machine learning models tend to give us a very good answer under normal circumstances but there will be no reasoning on how the conclusions or predictions were made. It is therefore often referred to as a black box. We don’t know what’s in the black box. Even if we do by illustrating the ML neural networks, chances are we won’t be able to explain it rationally. What made things more challenging (I am ranting again…) is the opacity of the input data to the black box. Data science researchers need to be very careful when handling and documenting the training data because they determine the sensitivity and operational range of your model. However, that’s just me training my own model for research. Do we know exactly what data Google uses to show stuff to us? So we have no clue how the machine works nor how the machine gets its knowledge from.
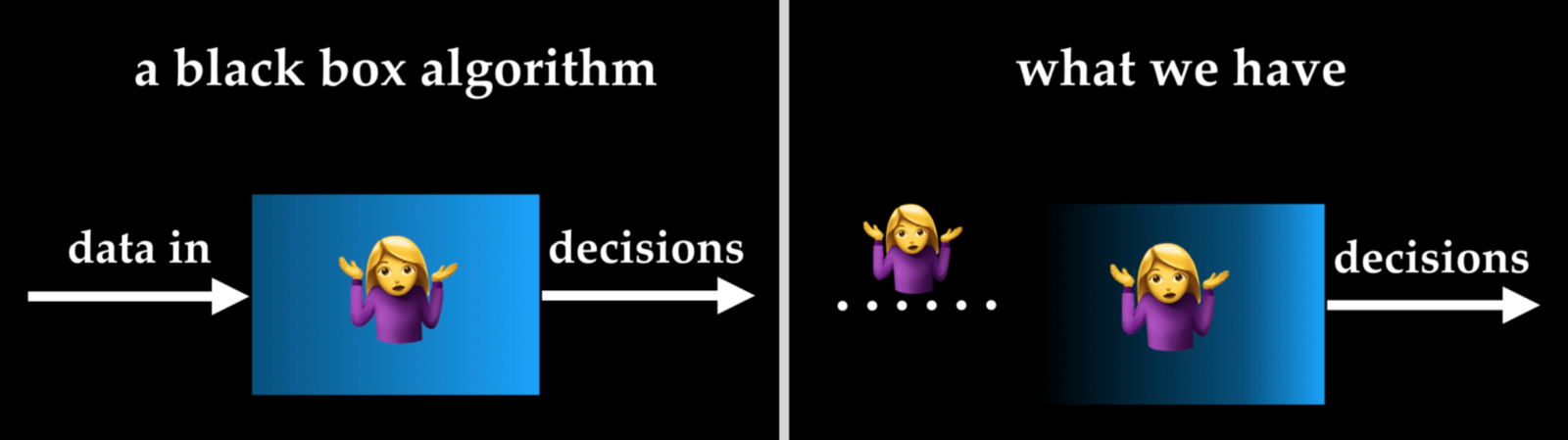
Some may argue that they don’t really care about how things were done as long as we have a good result. This kind of attitude has helped the function-based ML to thrive in the past few years. We are now getting used to the convenience enabled by ML-based software and services without bothering about the whys.
So is reasoning still relevant?
Even if we don’t expect a machine to ever be as smart as humans, we still need results interpretable to ensure fairness, transparency, and accountability. The fairness concerns with whether resources are shared “equally” between parties or whether a rule is applied consistently. Many researchers including myself argue that fairness is subjective and therefore needs to be measured at the user level. We spent a lot of time looking into human factors (sensual, perceptual, societal, etc.) and studying how the machine can take into account individual preferences and experience. However, I often feel what we do is an exercise of incorporating biases. The algorithm would allocate more resources to picky users and hungry user devices so that there is minimum QoE (quality of user experience) discrepancy across a group of users. You might disagree with my understanding of fairness but at least we are able to discuss what’s right and wrong based on my reasoning. With a high degree of complexity, an ML model can produce excellent outcomes with the wrong reason. The image below from Dr Kasia Kulma’s talk is a perfect showcase. The model which achieves high precision in classifying wolf and husky apparently recognise wolves by detecting snow in the picture. It certainly capitalised on the high probability of snow and wolf co-appearance in an image: a smart move to deliver results but not necessarily what we consider as intelligent. For fairness, the reasoning often outweighs the outcome.

The transparency is a measure for the general interpretability or opacity. There are different opinions on the measurement target. Some believe it’s about the model itself (i.e., the interpretability of how the model works). However, this might be too much to expect for intricate deep learning models. Furthermore, forcing higher transparency affects how models are built and potentially limit the use of some useful features. There is generally a trade-off between transparency and model performance. As a compromise, the interpretability can be set on the results coming out of a model rather than the model itself. This means that we attempt to interpret how the input features impact the results (on a much smaller scale). It would also enable some hypothetical reasoning to support humans to optimise a solution.
When it comes to using ML in critical missions such as performance review, credit rating, and autonomous vehicles, the main concern is people can get hurt when things go wrong. And that may be due to the wrong usage of training data or the algorithm itself. Ultimately, humans are accountable for what machines do. Even if its something that the machines taught themselves to do, its human who instructed the learning process. Prof Ben Shneiderman‘s talk covers this topic quite extensively from an HCI perspective. However, not many people consider the human-computer relationship as part of ML/AI research. Zero-control automation has a pivotal role in future network and system designs: it’s impractical to get human to make every single decision and we want to reduce human errors when humans are involved in decision making. Therefore, algorithm accountability is a technical challenge but perhaps more of a regulatory challenge.
[to be continued]

One thought on “Some thoughts on Artificial Intelligence – Part 2: Yes but why?”