This blog series discusses some R&D work within an ongoing “Big Idea” project. The project is in collaboration with the Big Film Group Ltd , a leading Product Placement Agency working with Blue Chip clients across UK and International entertainment properties.
Background
Currently as part of the service the company offers to clients an evaluation on the impact of product placement on TV programmes and films. The service is essential to the customer experience and the growth of business. The evaluation is carried out via human inspection over programmes to mark all corresponding appearances and mentions within the content of broadcast media, mainly TV and film. This is a manual operation which is time-consuming, requires intense concentration and costly. We believe that this whole process can eventually be automated using media processing techniques, AI and machine learning. [project design document]
The long-term goal would be to offer a monitoring service across all broadcast media which would allow agencies and their clients to know where, when and how their brands and companies are being talked about on air. For PR, Advertising and Social Media agencies this information would be particularly valuable. There is no existing solution readily available and we believe that there would be high demand for information and services of this nature. [project design document]
The first phase of the project is to prototype a core function: product detection. We want something that can detect Coca-cola products in sample videos provided by the company. The H.264/AAC encoded sample videos are roughly 40 seconds long and in the resolution of 1920×1080 and frame-rate of 25 fps. Coca-cola products appear in various points of the sample videos for the duration between half a second and several seconds.

Requirements
It is quite clear that we can map the core function to a ML object detection problem. Object detection has seen some major development with success in the past 5 years. So our focus is to analyse the requirements and pick the best from existing framework to develop a working solution.
- Requirement 1: Logo detection. To simplify the solution, we start with logo detection. This means that we do not differentiate different products/packages of the same brand nor their colours. So Coca-cola cans and glass bottles are considered the same.
- Requirement 2: Accuracy. The goal is to reach near human level accuracy overall but there are some major differences between the two. With human inspections, we expect few false positive (FP) detection but a degree of false negative (FN) when very brief appearances of product are not picked up by human eyes. For ML based solution, detection can be carried out frame-by-frame but there is a good chance of both FP and FN.
- Requirement 3: Speed. As we are prototyping for video, the speed of the framework is important. There is no hard requirement on processing framerate but few people would like to wait an hour or two of processing time on each TV show and movie.
- Requirement 4: End system. We are setting no constraint on end systems (both for training and runtime). We’ll develop the application in a physical workstation (not virtualised) while assuming a similar system will be available at runtime. It is possible to move the system at runtime to the cloud.
Framework
Two things constitute an object detection task: localisation (where things are) and classification (what it is). 1) Localisation predicts the coordinates of a bounding box that contains an object (and the likelihood of an object existing in that box). Different framework may use different coordinates system such as (x_min, y_min, x_max, y_max) or (x_centre, y_centre, width, height). 2) Classification tells us the probability of the object in the bounding box belonging to a set of pre-defined classes OR a distribution of probabilities of the object belonging to a set of pre-defined classes when the classes are exclusive (i.e., when it cannot be associated with multiple classes).
There are two main ML framework families for object detection: Region-Based Convolutional Neural Networks (R-CNNs) and the You Only Look Once (YOLO). Both frameworks have seen some major updates in the pass few years. Without going into the technical details too much, I’ll compare the two and discuss the reasons of our choice.

R-CNN is one of the first end-to-end working solutions for object detection. It selects regions that likely contain objects using selective search, a greedy search process that finds all possible regions and selects 2,000 best ones (in the format of coordinates) . The selected regions then go through ConvNet feature extraction before a separate classifier makes predictions for each region. R-CNN splits key functions in independent modules which is a reasonable choice for prototyping and it has shown a relatively good performance. The main issue of R-CNN is its speed. As thousands of regions go through ConvNet for each image, the process can be extremely slow. Processing a single image can take tens of seconds.

Fast R-CNN and Faster R-CNN introduced some significant architectural changes in order to improve the efficiency of the process (hence the names). The changes include shifting ConvNet to an earlier stage of the process so there is less (no) overlap on ConvNet operations over each image. The functionalities of ConvNet is also extended beyond the initial feature extraction to support region proposal (Region Proposal Network (RPN)) as well as classification (replacing SVM with ConvNet+activation function such as softmax). As a result, the architectural components also become more integrated. Faster R-CNN can process an image in less than a second. In summary, the R-CNN family started from a good performance baseline then gradually improved its speed to achieve “real-time” detection. Detectron (Mask R-CNN) is a good starting point to test out recent development on R-CNN.
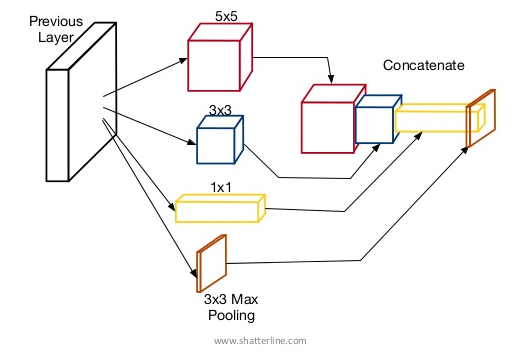
Compared with R-CNN, YOLO is designed for speedy detection when accuracy is not mission critical. Instead of searching for appearance of objects in every possible location, YOLO uses a grid-based search. The grid fixes the anchor points in each image and a number of (such as 3) bounding boxes are created at each anchor point. The grid size is determined by the stride when convolution operations are applied to the image. So for a 416 x 416 image, a stride of 16 will result in a grid of 26 x 26. A large stride means a greater reduction to the feature image dimension, hence it allows the bounding boxes to cover large objects. This design is inspired by the Inception model behind GoogLeNet. Instead of constructing a very deep sequential CNN and relying on small features to build up larger features, filters of different sizes operate in parallel and the results are concatenated. This is similar to having telephoto, prime, and wide-angle camera lens on your smartphone shooting at the same time, so you are picking up small, medium and large objects in one shot.
The standard configuration of YOLO has three stride sizes 32, 16, and 8 (which map to 13 x 13, 26 x 26 and 52 x 52 for a 416 x 416 image), each responsible for object of small, medium and large sizes. So the three grids will generate 13 x 13 x 3+26 x 26 x 3+52 x 52 x 3 bounding boxes as a fixed and manageable starting point. Because we are doing a sampled search and not full search, some objects might be missed. But thats the cost of a speed-first approach. In fact, the stride-based dimension reduction (and not ConvNet+maxpooling) is also a choice for speed and not for accuracy.

YOLO has three major releases: YOLO: YOLO Unified, Real-Time Object Detection, YOLO9000 – Better, Faster, Stronger, and YOLOv3: An Incremental Improvement. Each version is an attempt to improve model performance while maintaining the speed for real-time object detection. YOLOv3 uses a deep 53 layer ConvNet darknet-53 for feature extraction followed by another 53 layer ConvNet for detection at three size levels. So the 106 layer architecture is fully convolutional (FCN) and does not contain any conventional Dense layers. A connected Dense layer requires input data to be flattened, so it limits the size of input images. So a FCN design gives us the freedom to use any input image size (not without its own problems), a key feature for dealing with high res content such as HDTV.

The figure above compares the performance (Mean Average Precision mAP) and speed of some modern object detection models. mAP is a measurement that factors in both localisation accuracy (IoU) and classification accuracy (Precision-Recall Curve). COCO is a tough dataset to get good mAP so anything above 50@mAP0.5 is considered amazing. YOLOv3 clearly shows its advantages in speed (authors put then “off the chart” to make a point…) while its performance is on a par with others. It is also noticed that larger input images (such as 608 x 608) can help with YOLOv3’s performance with some penalty on speed.
It is important to point out that the performance comparison from the related work may not apply to our problem space. These models are likely to behave differently over high res image data extracted from video content. Based on the project requirements, phase 1 will have YOLOv3 as our reference framework.

4 thoughts on “Product detection in movies and TV shows using machine learning – part 1: background”