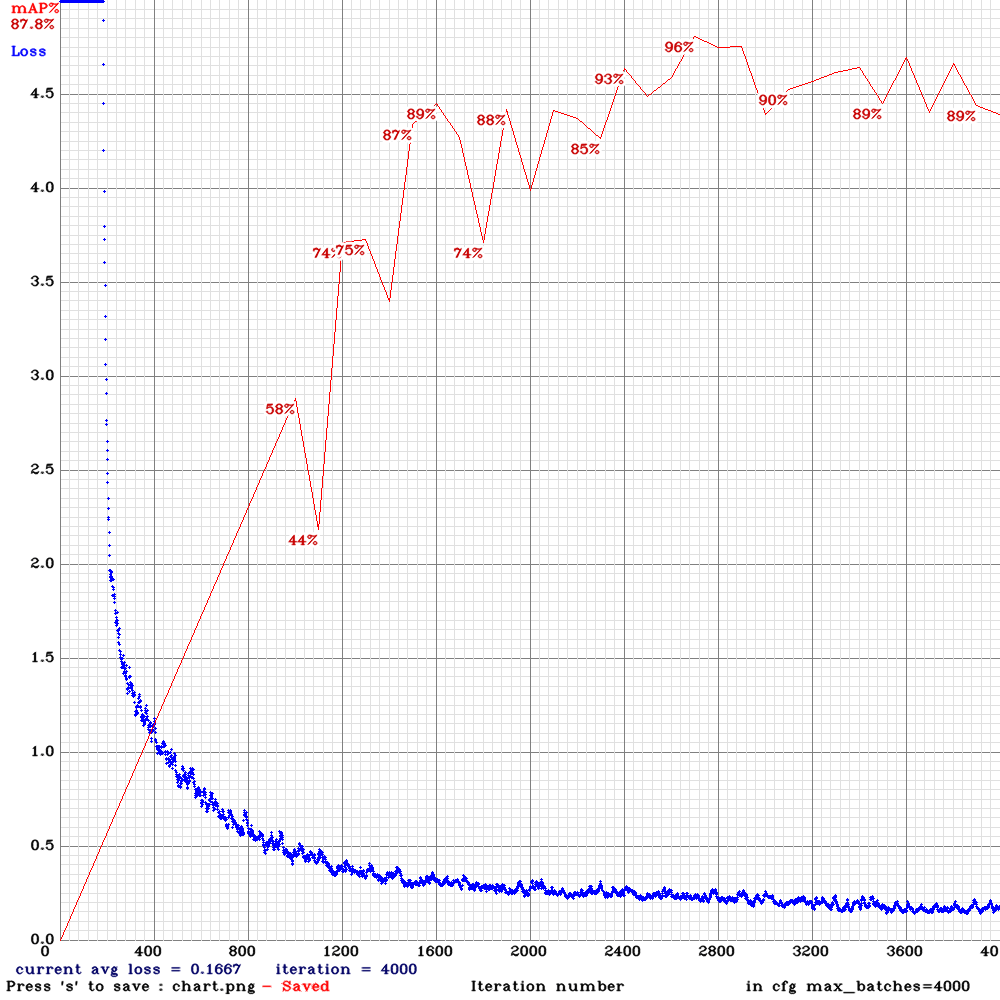
Training has been an ongoing process to test what configurations work for our us the best. Normally you set the training config, dataset and validation strategy then sit back and wait for the model performance to peak. Figures below show plots of loss and mAP@0.5 for 4000 iterations of training with input size of 608 and batch size of 32. Loss generally drops as expected and we can get mAP around 90% with careful configurations. The training process saves model weights every 1000 iterations plus the best, last and final version of weights. The training itself takes a few hours so I usually run it overnight.

The performance measures are based on our image dataset. To evaluate how the model actually performs on test videos, it is essential to do manual verification. This means feeding the videos frame by frame to the pre-loaded model then assemble the results as videos. Because YOLO detect objects at 3 scales, the input test image size has a great influence on recall. Our experiments suggest that the input size of 1600 (for full HD videos) leads to the best results. So input HD content are slightly downsampled and padded. The images below show the detections of multiple logos in the test video.


It is clear that training a model on image dataset for video content CAN work, but there are many challenges. Many factors such as brightness, contrast, motion blur, and video compression all impact the outcomes of the detection. Some of the negative impacts can be mitigated by tuning the augmentation (to mimic how things look in motion pictures) and I suspect a lot can be done once we start to exploit the temporal relationship between video frames (instead of considering them as independent images).
Product detection in movies and TV shows using machine learning – part 1: Background

Hi Dr Mu Mu, my problem is how to plot a mAP after every 50-60 iteration. In my documentation(Mr. AlexeyAB) until 1000 iteration, but i want in every 50-60 iteration. How can i appear before 1000 iteration? As far as I can see you have achieved this. Thanks in advance
The mAP plotting (-map flag) starts at 1000 iteration and becomes more frequent afterwards. I didn’t have to make any changes but I suppose you can do some reconfiguration in the source code?