In Part 4, I made a start with establishing a new training dataset by harvesting publicly accessible photos on social media. The main benefit of using user generated content is that they were taken in a real-world setting, hence close to what the targeting logos would look like in a film. For content selection and labelling, my own filtering tool and Yolo_Mark worked pretty well. It wasn’t easy to label 600+ images but the workflow is decent. The three classes are: 0 – Cadbury, 1 – ROSES, and 2 – HEROES. There are some typeface variations of ROSES. You need to be patient and consistent of the labelling strategy. As humans, we are able to acquire information from different sources very quickly while making a decision. So if I were actively looking for a particular logo while knowing the logo is definitely present, I could still point at an unidentifiable blob of pixels and be 100% certain that its a Cadbury logo on a discarded purple wrapper. It may not be realistic to expect a “low-level” machine learning model with a small training set to capture what human could do in this case. Therefore I limit the labelling to only the logos that I could visually identify directly.

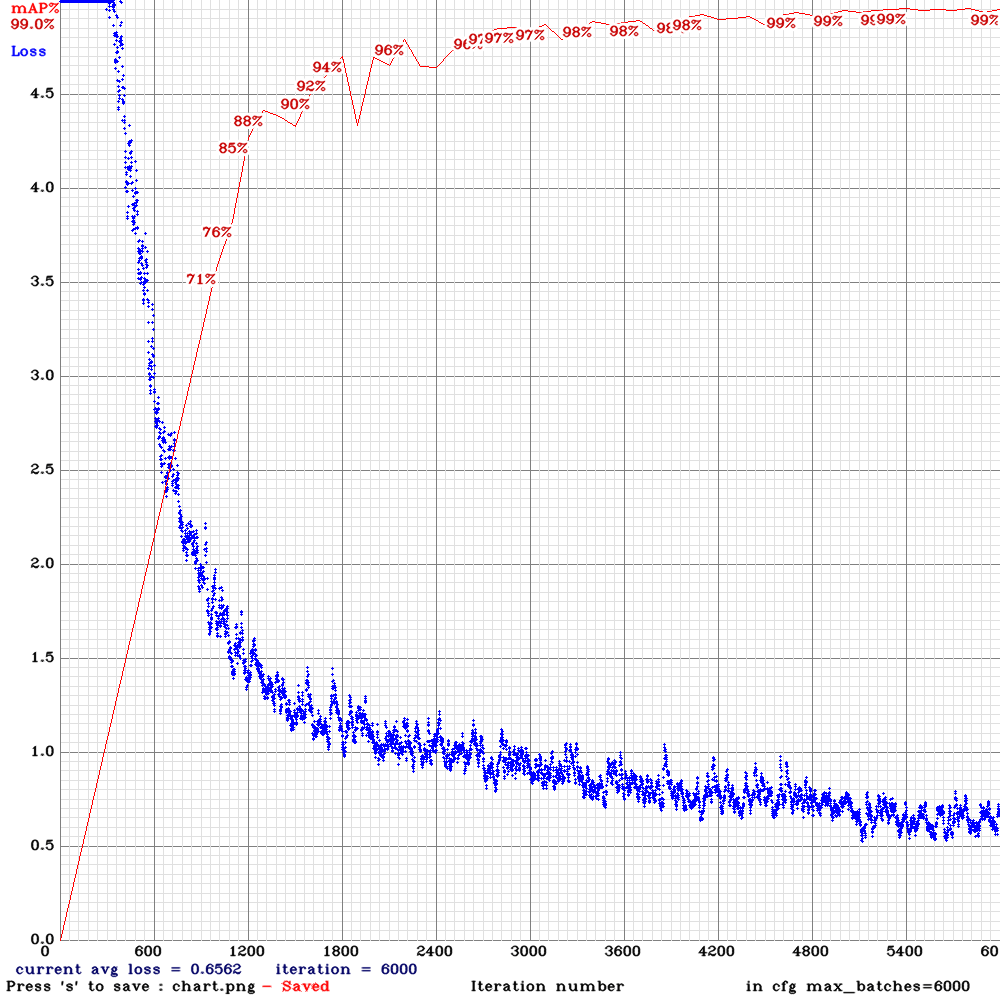
The training process wasn’t much different from the previous modelling for Coca-cola logo except some further tidying of the dataset (minor issues with missing files, etc.). With a baseline configuration, it took about 6 hours to complete 6000 epochs with a pretty good result base on the detection of three logos.
The images below illustrate what the model picks up from some standard photos (using the slider to see “before” and “after”).


Another example:


I’ve also tested the model on some videos provided by our partner. I won’t be able to show it here due to copyrights but its safe to say that it works very well with room for improvements. Some adjustment can be done at the modelling side, such as increasing the size of training images (currently downsampled to 608×608), increasing the number of detection layers to accommodate a larger range of logo sizes, or perhaps giving the new YOLOv4 a go!
This update concludes the “Product detection in movies and TV shows using machine learning” series. The dataset used for Cadbury, Roses, and Heroes training will be made public for anyone interested in giving it a go or expanding her own logo detector. I am still pushing this topic forward and will start a new series soon!
Product detection in movies and TV shows using machine learning – part 1: Background
Product detection in movies and TV shows using machine learning – part 3: Training and Results
Product detection in movies and TV shows using machine learning – part 4: Start a new dataset
